


















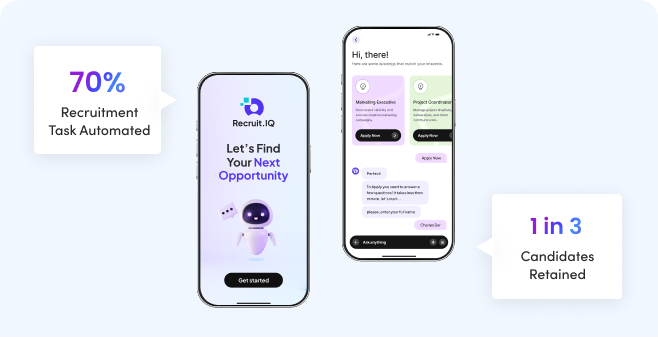
Challenges
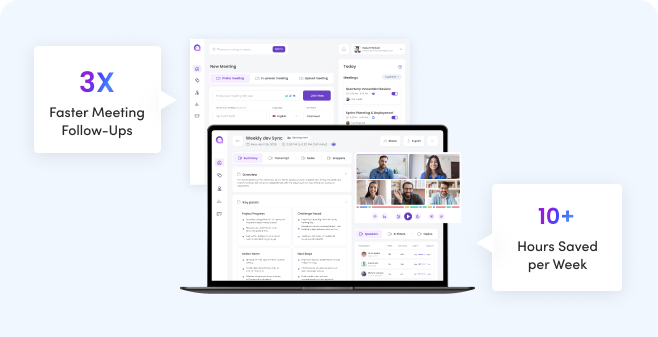
The platform lacked advanced automation. Screening, candidate queries, and data updates still needed human involvement.
Solutions
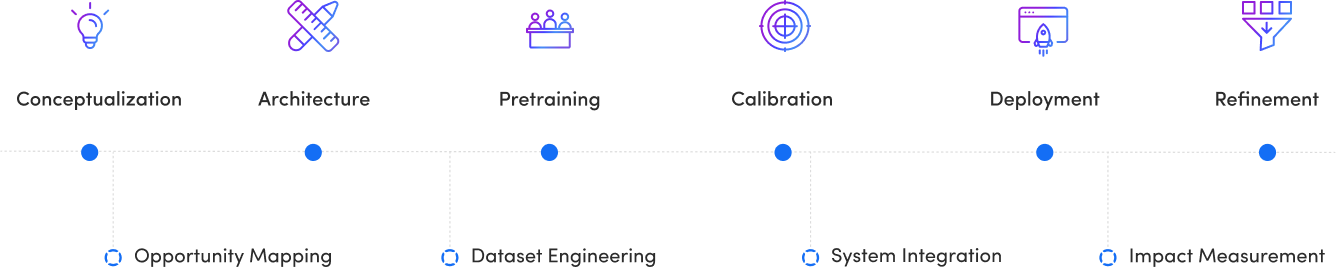
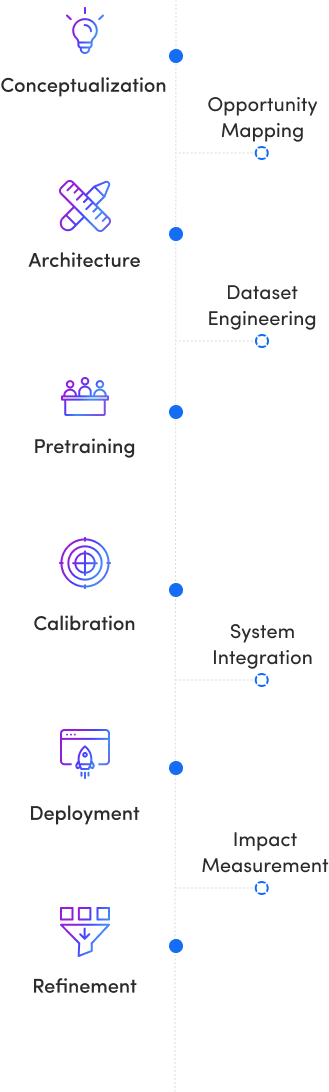
Radixweb developed a custom LLM-powered (GPT-3.5) chatbot to automate candidate interactions and screening conversations.