
Read More

Outstanding IT Software at the 2026 TITAN Business Awards - Read More
Machine Learning Lifecycle: From Data Collection to Model Deployment

Dhaval Dave
Published: Mar 12, 2026
ON THIS PAGE
Summary: Great models do not pay off on their own – they are engineered for success through repeated ML lifecycles. They turn scattered data programs into high-ROI AI projects, delivering accurate insights, staying aligned with business goals and maintaining resilience against drifts. This piece educates you about the right MLOps approach – data preparation to disciplined modelling, continuous monitoring for reliable outputs, intelligent automation and trusted scaling across the AI landscape.
TL; DR:
● Why It Matters: An efficient ML life cycle transitions pilots into production-scale solutions: improved accuracy, lesser drifts, reduced risks and auditable AI outcomes.● What Are the Core Stages? Problem definition → data collection → preprocessing/EDA → feature engineering → model selection & training (with cross‑validation) → evaluation → deployment → continuous monitoring & retraining.● What’s In for Businesses? Premium model reliability, lower operational costs, swifter time-to-impact, provable and enforceable governance, easily AI scalability and operationalization.● How To Do It Right? Treat data as product: steady versioning, automated CI/CD pipelines, monitor experiments, validate innovation with real-world metrics and cost-effectivity.● Deploying It Right: Ship with safe rollouts (shadow/A/B), integrate deep observability (drift, latency, payload logging), set transparent triggers to maintain accuracy in dynamic environments.● How Radixweb Helps? KPI-first scoping, strong data/feature pipelines, reproducible experiments, Kubernetes deployment, steady monitoring – end-to-end enablement.
Data in brilliant pilots doesn’t mean big wins for your business, unless it delivers brilliantly in actual production. The difference between a demo-led ambition and durable, production-grade impact is bridged through the process of machine learning. It aligns data strategies, models and operations so that each release delivers safer and better value than the last.
Leaders looking at maximizing value of the AI investments know it’s important to treat data as a product. But recent machine learning statistics also trigger a new pattern. Treating ML as a product, investing in production-ready MLOps strategy and consulting and ML model lifecycle thinking, makes their models cost-effective, compliant and observable. We have guided multiple businesses towards retraining, recalibrating, re-shipping ML models with confidence through:
- KPI-first scoping
- Reliable pipeline engineering
- Deploying model guardrails
- Continuous monitoring for drift and decay
This piece is your enterprise-ready machine learning development lifecycle guide that packs realistic insights – from data collection, prepping, customizing tech stacks, streamlining the regulatory landscape to building and deploying machine learning models. Let’s begin:

What Is Machine Learning Lifecycle?
The machine learning lifecycle is the process of defining business problems, collecting and preparing data, engineering features, training and validating AI models, deploying them into production stage and implementing continuous monitoring mechanisms to enhance their performance.
ML lifecycles build structured sequences of stages that ensure your ML models remain scalable, accurate and aligned with realistic business goals throughout their operational lifespan.
In reality, the ML model lifecycle is a holistic, step-by-step workflow that encompasses problem definition, preparing data for model development, deployment and continuous monitoring – the most crucial aspect of designing and building AI powered software systems. It is an iterative cycle that continuously evaluates, optimizes, retrains models with evolving business needs. The success of ML models largely depends on matured lifecycles as they integrate deeper transparency, consistency and quality assurance, helping businesses avoid risks of unreliable predictions, costly reworks and flawed process execution.
Key Characteristics of ML Lifecycle Workflows:
- Structured & Sequential: From idea to production – clear, sequential stages guiding teams through every step.
- Iterative & Ongoing: ML models are continuously re-optimized and monitored with changing conditions.**
- Cross-Functional: The stages involve teams across engineering, data science, DevOps, business stakeholders etc.**
- Quality-Driven: Prioritizes integrity, validation and governance of data at every level.
- Production-Focussed: Every step of deployment prioritizes observability, drift detection and maintenance.
Common Failure Points in ML Lifecycles:
- High Post‑Deployment Failure: Almost 85% of ML deployments fail after deployment, often due to undetected, silent drifts and poor monitoring.
- Low Production Success Rate: Only 32% of ML models successfully move from pilot to production due to poor deployment maturity.
- Poor Data Quality: Inconsistent data quality is a core lifecycle weakness. 85% of AI models fail due to it.
- No Drift & Performance Monitoring: Models require constant monitoring of data drift, concept drift, and prediction drift to eliminate silent ageing.
- Immature MLOps Practices: Fragmented workflows, zero pipeline retraining, and silos between DS/engineering/IT functions cause MLOps challenges.
- Misaligned Business Objectives: Not starting with a clear business goal is a recipe for disaster. Prioritize alignment before writing a single line of code.
- Scaling Challenges in Large ML Workloads: Large‑scale training jobs (150M GPU‑hours, 4M jobs) depict strong vulnerability to failures in distributed environments.
- Weak governance & compliance: AI/ML is now a material risk in 72% of S&P 500 filings. But only 2% of enterprises meet basic governance standards.
What Are the Various Stages of the Machine Learning Lifecycle?
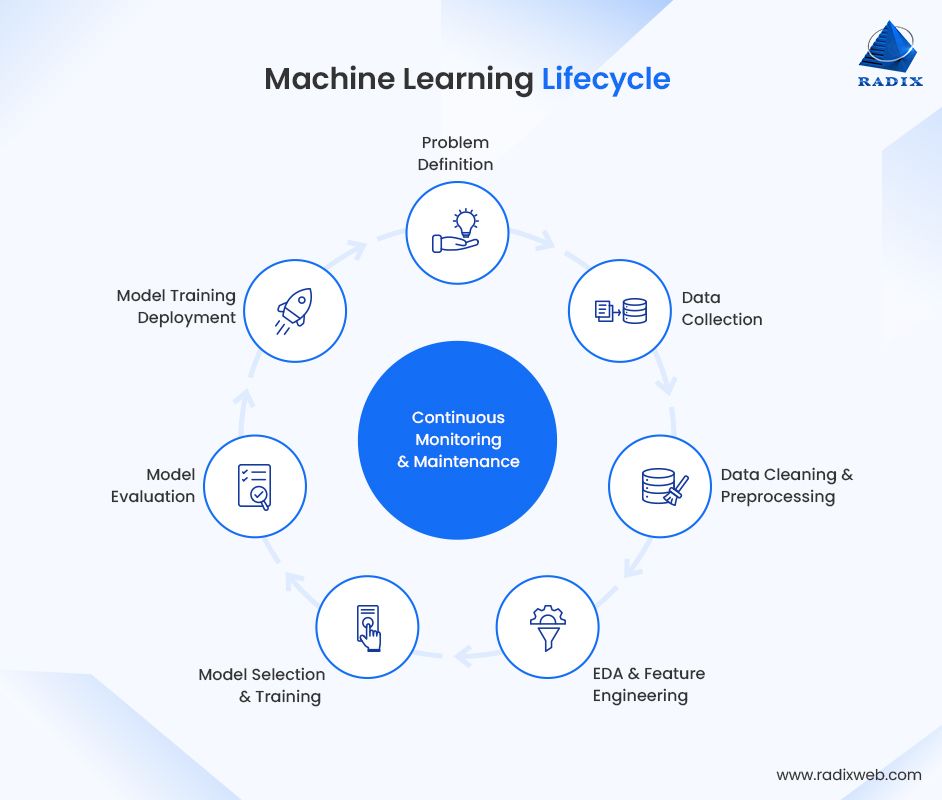
The step-by-step machine learning lifecycle looks like:
Problem Definition → Data Collection → Data Cleaning/Preprocessing → EDA → Feature Engineering/Selection → Model Selection → Training (with Cross‑Validation) → Evaluation → Deployment → Monitoring & Maintenance (Retraining triggers)
With the MLOps market projected to scale from USD 2,191.8 million in 2024 to USD 16,613.4 million by 2030, at a 40.5% CAGR, a Grandview Research study indicates a gigantic shift towards more mature and automated ML lifecycles.
Problem Definition:
For every aspect of replacing outdated systems with intelligent AI driven workflows, the first step remains identifying the key aspects to be improved. For eg. improve churn prediction in 30 days. Then define the metrics to be achieved (AUC/F1 and commercial KPIs like lowering attrition rates). You’ll also need to identify the key roadblocks and error trade-offs for your goals (like privacy, interpretability, explainability, latency and false positive vs false negative). When you define your core problems clearly, your engineering efforts fall in sync to deliver the desired value while the best practices can be prioritized across the lifecycle.
What Do We Do at Radixweb? Our process begins with a comprehensive discovery and scoping workshop wherein we prioritize model goals and guardrails before a single line of code is written, ensuring thorough ML model risk controls and lifecycle governance.
Data Collection:
The success of ML models directly depends on the quality of the training data. This training data for ML models is sourced from CRMs, ERPs, event streams, IoT sensors, third‑party APIs, and data lake signals. All of this demands a unified data and AI infrastructure that can handle ingestion, versioning and governance at scale. This is why businesses must implement systematic processes like schema contracts, data versioning, and an ingestion cadence aligned to model retraining to gather, clean and structure data so that it covers the full complexity of business processes.
What Do We Do at Radixweb? We build a cross-functional team with domain experts, data engineers, stakeholders who ensure aligning collected data with project goals for accurate predictions. Data preparation by Radixweb has enhanced model accuracy rates by 15-30%, reducing training tie by 50% and production challenges by close to 80%.
The Checklist We Recommend:
- Map Sources & Owners → Define SLAs, Lineage, and Consent Paths
- Version Datasets & Schemas → Build Reproducible Training Sets
- Plan Refresh Cadence → Supports Retraining Windows
Data Cleaning and Preprocessing:
Raw data is practically unusable for model training. Data preprocessing in machine learning consists of missing‑value detection, de‑duplication, outlier treatment, normalization/scaling, and categorical encoding. Most businesses tend to avoid this stage because its time consuming. Rigorous preprocessing of data is what builds the foundation in the process of machine learning and it starts with modernizing your data environment for reliable model training.
What Do We Do at Radixweb? We embrace techniques like mean/median or model‑based imputation; IQR or z‑score outlier handling; one‑hot/target encoding; standard/min‑max/robust scaling; domain‑specific transformations like text cleaning, time‑series resampling etc.
Exploratory Data Analysis (EDA):
The EDA stage helps you prioritize and explain the machine learning life stages like leakage risks, class imbalances, seasonality, spiky features, proxy biases etc.
What Do We Do at Radixweb? We position EDA to de-risk ML modelling. Our process includes using correlations, distributions, temporal plots, document findings for model selection and feature engineering.
Feature Engineering & Selection:
Feature engineering in machine learning is used to transform raw responses into predictive signals: rolling windows, lags, ratios, embeddings, and domain heuristics. This is combined with feature selection (filter/wrapper/embedded) to reduce latency and noise. This stage acts as a key bridge from data to modelling and a major lever for accuracy and stability.
What Do We Do at Radixweb? Our engineers productionize features through feature stores and embed directly in ML pipelins to promote reuse and parity in training-serving across teams,
Model Selection:
The choice of right ML algorithm and model architecture defines the baseline for project success. Evaluate multiple use cases on the basis of trade-offs in model complexity, interpretability, computational needs etc. Also consider business requirements, deployment constraints and data characteristics.
What We Do at Radixweb? We test numerous model architectures across the key metrics and have been able to deliver 20-35% elevated performances along with lowering resource usage by 40%.
What Do We Recommend? Choose strong baselines (like gradient boosted trees for structured data) over complex models for tabular tasks. Choose models that align with your interpretability needs, SLA constraints and data regimes (tabular vs unstructured).
Model Training (Designing Experiments):
Model training is a strategically organized process that weighs a model’s learning capacity against risk of overfitting. This stage needs continuous monitoring to ensure models operationalize, adjust and learn relevant patterns while maintaining generalization.
Businesses must invest strong training and validation protocols to build scalable, reliable, production-ready models and enterprise grade artificial intelligence systems that deliver sustainable value.
What Do We Do at Radixweb? We codify machine learning experiments with hyperparameters, seeds, and dataset versions. We also implement cross-validation strategies in machine learning, like time series, k-fold, stratified, etc., for estimating generalisations and apply regularizations early for eliminating overfitting.
What Do We Recommend?
Classification → Stratified k‑fold (k=5–10); Time‑series → forward chaining; Use nested CV for model/HP selection where data is scarce.
Model Evaluation:
Build a comprehensive evaluation process that ensures your machine learning models meet all tech and business needs before they are deployed. Systematic testing processing should be leveraged to assess model performance across the metrics of accuracy, fairness, resource efficiency and robustness. Build a collaborative team of tech specialists and stakeholders so that the results deliver true business value.
What Do We Do at Radixweb? We leverage multi‑metric scorecards: AUC/PR‑AUC ranking metrics, precision/recall/F1 classification, and MAE/MAPE/RMSE regression strategies, along with calibration and fairness analysis to eliminate costly production issues. Our teams also validate with robust splits for time‑dependent data, temporal holdouts. The CRISP-ML(Q) quality process model underline comprehensive evaluation before deployment, enabling teams to discover 80-90% of problems in the pre-deployment stage and cutting down production incidents by 75%.
Operational Checks We Recommend:
- Latency Under Peak Load
- Resilience to Missing Fields
- Sensitivity to Drift
- Alignment with Business Cost Curves
Model Deployment:
In the deployment stage, models are operationalized through real‑time APIs, batch jobs, or streaming. You must understand, modern tech stacks are extremely reliant on inference-servers, Kubernetes native orchestration and containerization for safe and scalable ML serving.
What We Do at Radixweb? Our AI experts integrate blue/green, A/B or shadow rollouts, payload logging, and performance dashboards, multi-model serving patterns, automated canaries to minimize risks while meeting SLAs. We also emphasize observability, drift detection, and explainability as mandatory for at‑scale ML.
Continuous Monitoring & Maintenance:
Business must take the post-deployment stage seriously by investing in continuous monitoring in machine learning models to ensures trust and accuracy.
What Do We Do at Radixweb?
We continuously track data quality, input/output drifts, model performance, latency, throughput, and cost. We also design and implement alerts to trigger retraining or rollbacks, payload logging, and dashboards for ongoing visibility.

Tools and Technologies Across the ML Lifecycle – What Do They Do?
Advanced machine learning functions depend on unified tool stacks that enables planning, experimentation, data pipelines, model development and deployment. Pipeline tooling, Kubernetes-native deployment with draft monitoring ensures producing reliable ML systems.
| Lifecycle Stage | Purpose | Common Tools & Platforms | How They Help |
|---|---|---|---|
| 1. Problem Definition & Planning | Define business objectives, feasibility & KPIs | Confluence, Notion, Jira, Miro | Supports documentation, collaboration, requirement mapping, success criteria design |
| 2. Data Collection | Ingest data from databases, APIs, logs, sensors | Apache Kafka, Apache NiFi, Airbyte, Fivetran, AWS Glue, Google Cloud Dataflow | Enables scalable ingestion, ETL/ELT workflows, and integration with diverse data sources |
| 3. Data Cleaning & Preprocessing | Handle missing values, outliers, normalization, encoding | Pandas, NumPy, Apache Spark, Databricks, Great Expectations, TensorFlow Data Validation | Ensures high‑quality, reliable training data with validation & automated checks |
| 4. Exploratory Data Analysis (EDA) | Understand distributions, patterns & relationships | Jupyter, Pandas-Profiling, Matplotlib, Seaborn, Plotly, Tableau | Provides visual insights into patterns, anomalies, bias, and feature behavior |
| 5. Feature Engineering & Selection | Create and refine predictive features | Feature Stores (Feast, Tecton), Scikit‑learn, Spark MLlib | Guarantees training‑serving parity, reusable features, and automated transformations |
| 6. Model Selection & Training | Build & train ML/DL models with experimentation | Scikit‑learn, XGBoost, LightGBM, TensorFlow, PyTorch, MLflow, Weights & Biases | Supports scalable training, tracking experiments, comparing models & tuning hyperparameters |
| 7. Model Evaluation & Validation | Assess performance, fairness & robustness | Scikit‑learn Metrics, Evidently AI, TensorFlow Model Analysis, AIF360 | Enables multi‑metric evaluation, fairness checks, drift analysis & regression tests |
| 8. Deployment & Serving | Serve models in production (real‑time or batch) | Kubernetes, Docker, Seldon Core, BentoML, MLServer, AWS SageMaker, GCP Vertex AI | Provides scalable, low-latency model serving with safe deployment strategies (A/B, shadow) |
| 9. Monitoring & Maintenance | Track drift, performance, latency, data quality | Prometheus, Grafana, Seldon Alibi Detect, Evidently AI, Datadog | Ensures long-term reliability with drift detection, automated alerts & performance dashboards |
| 10. MLOps & Pipeline Automation | Automate CI/CD for data, training & deployment | Kubeflow, Airflow, Prefect, Dagster, GitHub Actions, GitLab CI | Enables reproducible ML pipelines, automated retraining, governance & model lifecycle management |
How Radixweb Helps Building Contextual ML Lifecycles?
Establishing a strong ML lifecycle workflow demands KPI-led problem scoping and feasibility mapping for aligning data with business goals. At Radixweb, our strongest focus in the ML practice remains ensuring strong model quality, eliminating drift, keeping outcomes biased and safe. Over the last year, we have driven more than 50 pilot experiments to the production stage with safe automated pipelines, feature stores, enforceable pre-processing and lineage controls.
We implement cross-validations, reproducible experiments, and continuous retraining to ensure performance and long-term compliance. At Radixweb, our process is highly structured, we follow only the best practices for deploying machine learning models:
- Value Framing: KPI‑centric problem definition and feasibility mapping before each build.
- Pipelines & Feature Stores: Operationalizing data preprocessing techniques and features with lineage and contracts.
- Disciplined Experiments: Reproducible runs, cross validation in machine learning, and automated comparisons.
- K8s‑Native Deployment: Canary/shadow rollouts, payload logging, drift detection, and dashboards from day zero.
- Continuous Improvement: Threshold‑based retraining and versioning to keep models compliant and performant.
With more than two decades of deep industry experience, we have helped businesses across various sizes integrate smart AI capabilities, operationalize automation and delivered ROI-focussed growth. Our machine learning and AI specialists are always a scoping session away from transforming your idea into your personal growth engine.

Conclusion
The essence of machine learning development isn’t in shipping a model. At its core, it’s about shipping impactful outcomes. Just like data, ML needs to be treated as a product – leveraging data contracts, conducting reproducible experiments, safer deployments and continuous monitoring, risks can be mitigated and value compounded.At Radixweb, we help you build streamlined operating systems—from data collection to model deployment and beyond. Partner with our ML engineering team if you want your models stay accurate, observable, and auditable as your business scales.
Frequently Asked Questions
What are the main stages of the machine learning lifecycle?
Why is data collection important?
How are models selected and trained?
What does model deployment mean?
Why is monitoring critical after deployment?

Explore More Topics
Ready to brush up on something new? We've got more to read right this way.
Get top Insights and news from our technology experts.