Read More

Recognized for AI Excellence at 2026 Globee® Awards - Read More
AI-Driven Data Engineering: How Machine Learning Models are Shaping the Future of Healthcare Data Pipelines

Rahul Shrimali
Published: Nov 20, 2025

ON THIS PAGE
- Purpose of This Blog and Why Read It
- Understanding Data Engineering Processes in Healthcare
- How AI/ML Improves Healthcare Data Pipelines
- Benefits and Use Cases of AI in Healthcare Data Engineering
- Challenges of Using AI/ML in Healthcare Data
- Best Practices for AI Data Pipeline Implementation
- The Future of AI in Healthcare Data Engineering
- What Healthcare Leaders Should Do Now
ON THIS PAGE
- Purpose of This Blog and Why Read It
- Understanding Data Engineering Processes in Healthcare
- How AI/ML Improves Healthcare Data Pipelines
- Benefits and Use Cases of AI in Healthcare Data Engineering
- Challenges of Using AI/ML in Healthcare Data
- Best Practices for AI Data Pipeline Implementation
- The Future of AI in Healthcare Data Engineering
- What Healthcare Leaders Should Do Now
Summary of the Blog: In light of the expanding reach of AI in healthcare data engineering, this blog walks you through the change. Discover how ML models are improving data pipelines, explore the top real-world use cases, learn best practices our teams have refined over time, and understand the practical next steps to prepare your organization for this shift.
Until very recently, healthcare institutes and service providers had very little control over their own data. There were always massive amounts of unstructured data sitting in EHRs, diagnostic images, device telemetry, and clinical notes, but only a fraction was ever used, 3% to be precise.
That’s out of nearly 50 petabytes of data a single hospital produces each year. The remaining 97% was often discarded or needed manual handling.
It wasn’t a lack of intent from enterprises though; the problem was in the infrastructure. Legacy ETL systems were not meant to handle such complexity and nuances of modern data engineering. Privacy regulations also posed a restriction on data exchange, and unstructured clinical text was always beyond the reach of analytics. We’re talking about the years from 2010 to 2018, and in some cases, well into 2020.
But the recent progress in AI and ML has changed that equation. With AI-driven data engineering practices, pipelines can read, classify, anonymize, and integrate information from thousands, even millions of clinical and operational systems in near real time.
Since healthcare digital solutions are one of our strongest focus areas, we had to keep a close watch on how optimized AI data pipelines are changing the picture. Recent breakthroughs like NLP-based clinical coding, automated PHI de-identification, ML-driven patient matching, and AI-assisted FHIR mapping are making healthcare data 100% interoperable and insight-ready. Nothing really slips through the cracks.

The Purpose of This Blog and Why You Should Read It
For this blog, we reached out to our senior data engineers who’ve specifically worked with hospitals and MedTech firms. Their perspective and the information we gained shaped much of what you’ll read here.
The consensus is this - AI is transforming the healthcare industry at an unusually brisk pace. And you can see the momentum in the way modern data pipelines are being designed around MLOps practices. Waiting too long to modernize will make that gap almost impossible to close later, once AI-driven interoperability and automation become industry standards, after the boom turns into a baseline expectation.
On this point, Pratik Mistry, who leads Technology Consulting at Radixweb, makes an important observation:
“Healthcare has probably gained the most from AI so far. Those are the foundations that make every advanced use case possible. The challenge now is speed. The ones who start early will build smarter systems. The rest will just play catch-up.”
If you haven’t started exploring how AI/ML improves healthcare data workflows yet, this is the moment to begin.
Explaining the Process of Data Engineering in Healthcare
The process starts with data ingestion. Data from multiple systems (EHR, LIMS, PACS, billing, IoT devices) is extracted and loaded into a repository or data lake. Then comes data standardization, where formats are aligned to healthcare standards like HL7 or FHIR.
Next is data transformation and cleaning, the stage where automation plays a huge role in structuring clinical text, detecting anomalies or duplicate records, and removing PHI to maintain compliance with HIPAA or GDPR.
After cleaning, healthcare data engineers create data pipelines that automate movement from raw storage to analytics systems. The last phase is data governance and lineage tracking to ensure all the data elements are secure and auditable.
Modern data engineering has shaped much of healthcare’s digital transition, yet the new generation of artificial intelligence has moved the field forward in ways that weren’t possible before. Here’s how it’s changing.
How AI/ML Models Enhance Data Engineering in Healthcare and Optimize Each Pipeline Stage
Artificial intelligence and machine learning now function as an embedded layer in healthcare data pipelines. Every stage that had to have manual configuration can now be supported by adaptive models that learn from historical behavior and system feedback.
To see what that really means in practice, it helps to walk through each stage of the data pipeline and where AI makes a difference.
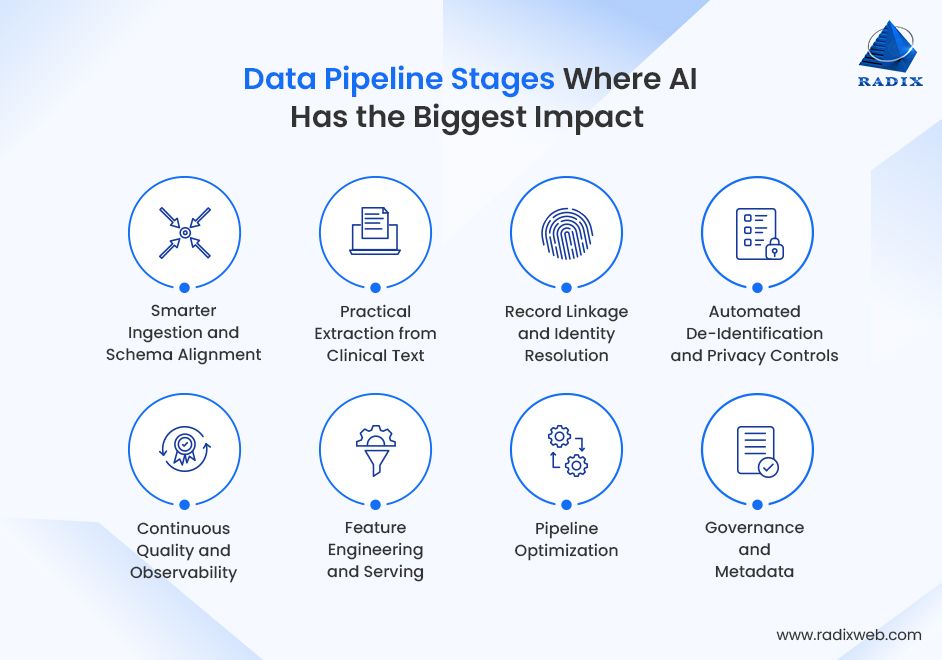
1. Smarter Ingestion and Schema Alignment
Incoming data in healthcare comes from hundreds of disjointed systems. ML models can recognize and classify these feeds even with different formats like HL7 messages, DICOM metadata, device telemetry, or free-text notes.
There's no need for manual mapping. Embedding-based similarity and supervised classifiers suggest canonical fields. It also reduces onboarding time for new sources and speeds conversion to FHIR resources. All of this results in a stark reduction in repeated effort that was previously needed to create customized parsers for every vendor export.
2. Practical Extraction from Clinical Text
Medical datasets are mostly inconsistent in units, terminologies, formats, or values. ML models learn these irregularities from historical corrections and automatically align entries to standard vocabularies like LOINC, SNOMED, or RxNorm.
Natural language processing solutions have proved to be highly useful in these tasks. This particular subset of AI is increasingly applied to extract discrete concepts from progress notes, discharge summaries, and pathology reports, and produce coded outputs.
We’re thus seeing a growing popularity of AI-driven normalization tools in healthcare (IMO Health is a great example). The net effect is that narrative records become usable in analytics and cohort selection without large teams of annotators.
3. Record Linkage and Identity Resolution
Identifying unique patients across fragmented systems has been a long-standing issue in healthcare. It’s a common challenge, but machine learning models built for probabilistic matching and similarity learning can usually reconcile patient records when identifiers are incomplete or inconsistent.
These models evaluate similarity across demographic, temporal, and clinical variables to determine whether records belong to the same individual. Advanced solutions extend this logic with embedding-based matching that captures subtle correlations beyond simple field comparison. Healthcare service providers get more reliable longitudinal patient records, which is essential for analytics and research.
4. Automated De-Identification and Privacy Controls
Another application of AI in healthcare data engineering is automated de-id systems. Data must retain analytical value and protect patient privacy. AI tools automate this process by detecting and masking protected health information across structured fields and free-text documents.
NLP once again works as the core mechanism here. It locates names, addresses, or identifiers, computer vision solutions scan image metadata, and context-based models decide when to replace data with realistic synthetic equivalents. There are now reports of large real-world NLP systems that processed and de-identified hundreds of millions or more clinical notes with independent certification for production use.
5. Continuous Quality and Observability
AI supports continuous data quality oversight. It performs exceptionally well in learning baseline distributions and identifying deviations. ML systems flag distributional shifts, sudden drops in completeness, inconsistent coding, or schema changes that might break downstream analytics.
Anomaly detection models classify data quality incidents and rank them by business impact. As a result, medical teams can prioritize remediation efficiently without any surprise failures in production analytics and clinical decision support.
6. Feature Engineering and Serving
Once data is standardized, ML contributes to generating higher-level attributes that feed predictive models or population studies. Algorithms can derive patterns such as medication adherence rates, episode timelines, or lab trend indicators from raw data.
Automated feature engineering platforms evaluate feature stability and correlation to prevent drift and redundancy. Data scientists can focus on hypothesis design, not mechanical variable preparation. Outcomes here are practical - shorter model development cycles and fewer feature-related production incidents when teams adopt feature stores and automated feature-stability checks.
7. Pipeline Optimization
Brute-force scaling used to be the target state for healthcare data pipeline optimization. Now, it’s about intelligence and timing. Predictive scheduling and adaptive resource allocation are at the core of how teams run their workloads.
In practice, models forecast upcoming demand, adjust cluster capacity on the fly, and even reorder processing tasks to keep throughput steady. Cost-optimization agents quietly watch historical pipeline metrics and spot where performance can be maintained without over-provisioning. Such reliable, real-time performance doesn’t burn unnecessary compute or cloud spend.
8. Governance and Metadata
AI-assisted cataloging has become one of the most practical upgrades in automated healthcare data systems. These tools automatically classify incoming datasets, tag sensitive attributes, and maintain an ongoing record of data lineage.
Behind the scenes, metadata extraction models read schema definitions and pipeline logs to build a full lineage graph, something that once took teams weeks to document manually. The outcome is a governance layer that makes data far easier for analysts and clinicians to find, trust, and reuse.
If you’d rather visualize it all at a glance, here’s a quick breakdown of how ML fits into each stage of the healthcare data pipeline:
| Pipeline Stage | ML Role | Outcome Example |
|---|---|---|
| Ingestion | Schema inference, semantic mapping | Map lab results to FHIR resources |
| Cleaning & Normalization | Pattern learning, NLP | Normalize clinical terms & abbreviations |
| Record Linkage | Probabilistic/embedding matching | Merge patient records across facilities |
| De-identification | NER & PHI recognition | Mask names, addresses, IDs from notes |
| Feature Engineering | Auto feature extraction | Build features for disease prediction models |
| Quality Monitoring | Anomaly & drift detection | Identify abnormal lab trends |
| Optimization | RL-based scheduling, auto-scaling | Optimize ETL job runtimes |
| Governance & Metadata | Embedding-based search | Auto-tag datasets with clinical concepts |

Top Benefits and Industry Use Cases of AI in Healthcare Data Engineering
Looking at the recent trajectory of AI adoption in healthcare, the last few years have been a turning point. The pace of innovation has been remarkable and deeply integrated into everyday workflows. New use cases appear constantly, sometimes in places no one expected.
Here are some of the most relevant use cases of AI/ML optimized data pipelines where the impact feels most visible right now:
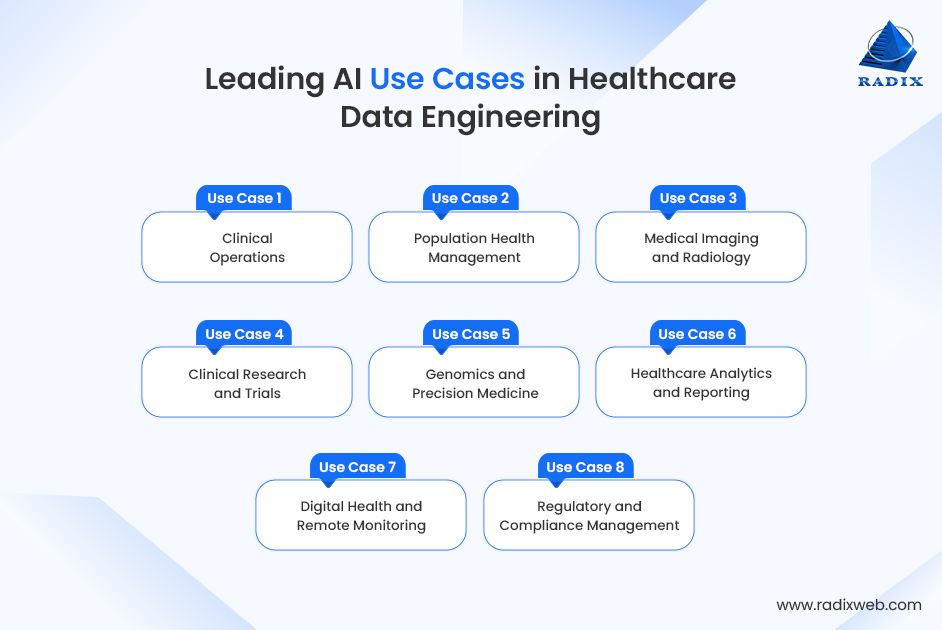
Use Case 1: Clinical Operations
AI-powered data pipelines are the key enabler here. These pipelines manage real-time data ingestion from multiple hospital units and feed validated data to operational models. This is an innovative example of using AI to automate data validation in healthcare systems.
- Predictive scheduling models integrated within streaming ETL frameworks forecast admission surges.
- NLP modules extract key operational terms from physician notes during data ingestion.
- Real-time data validation layers flag anomalies before they propagate to downstream dashboards.
Use Case 2: Population Health Management
Data engineering for medical and population health used to be a cycle of periodic data aggregation. But AI has shifted it to dynamically updated streaming pipelines. AI models now harmonize unstructured datasets to automatically link patient records with payers, providers, and social health sources.
- Graph-based record linkage resolves fragmented patient identities across multiple EHR systems.
- ML classifiers tag social determinants of health attributes during data ingestion.
- Predictive pipelines score population risk dynamically and feed directly into care coordination platforms.
Use Case 3: Medical Imaging and Radiology
Imaging pipelines have grown from static repositories into intelligent, self-optimizing data systems. AI integrates directly into the data flow for each scan to be properly indexed, classified, and retrievable across systems.
- ML-based DICOM parsers auto-extract metadata and normalize formats for unified access.
- Vision models generate pre-screening scores that feed triage queues in PACS.
- Federated data pipelines support multi-hospital model training without sharing raw images.
Use Case 4: Clinical Research and Trials
Research pipelines now heavily rely on ML to automate eligibility screening, data curation, and compliance. AI supports end-to-end traceability from data ingestion through analysis. The end results are improved speed and audit readiness.
- NLP pipelines extract trial-relevant variables from EHRs and map them to protocol fields.
- De-identification models scrub PHI and preserve semantic structure for analytics.
- ML-integrated ETL provides consistent variable definitions in multi-site research environments.
Use Case 5: Genomics and Precision Medicine
AI models are deployed to handle the massive data loads and complexity that come with genomics. ML algorithms help standardize formats, extract important patterns, and interpret variations while fitting neatly into cloud data systems.
- Deep sequence models classify genomic variants during ingestion to reduce manual review.
- ML-assisted ETL automates alignment and annotation workflows using unified schema templates.
- Feature engineering pipelines merge genetic and clinical phenotypes for model training.
Use Case 6: Healthcare Analytics and Reporting
AI-optimized data pipelines are smarter and more self-adjusting than traditional pipelines. Instead of waiting for manual updates, AI keeps data fresh, flags drift automatically, and fine-tunes outputs. Teams get analytical reports that stay consistent with source data.
- ML-based data quality scoring gates defective datasets before they reach BI tools.
- Generative models compose executive summaries from structured metrics and contextual metadata.
- Predictive pipelines monitor ingestion latency to maintain timely reporting cycles.
Use Case 7: Digital Health and Remote Monitoring
AI-powered data pipelines are making some of their biggest strides in digital healthcare right now. Streaming pipelines now process millions of sensor readings per patient daily. AI and ML maintain these flows with minimal noise and automate classification/synchronization in device ecosystems.
- Online learning models distinguish valid clinical events from device artifacts.
- Predictive resource allocation adjusts compute for varying telemetry loads.
- Drift detection models track device accuracy degradation and trigger recalibration alerts.
Use Case 8. Regulatory and Compliance Management
Talk to anyone managing patient data today, and they’ll tell you about the role of AI in healthcare data compliance and security. Governance data pipelines now feature automated compliance monitoring, lineage tracking, and PHI detection powered by AI. ML models. Data transformations stay documented and policy-aligned, which is essential for HIPAA, GDPR, and GxP frameworks.
- ML classifiers tag sensitive attributes during data ingestion and transformation.
- NLP models analyze regulatory updates to identify impacted datasets.
- AI-based risk scoring models flag unusual access or data-sharing patterns.

Challenges of Integrating AI with Healthcare Data Pipelines
The problem areas mentioned below came from our own experiments, as well as from conversations with teams across hospitals, research institutes, and healthtech companies around the world.
The challenges of using modern AI models in healthcare data are surprisingly consistent - data quality issues, compliance hurdles, model drift, and data inconsistencies:
- Fragmented Data – Healthcare data still sits in disparate systems with different formats and coding standards. This issue is so prevalent that even firms with FHIR-enabled vendors struggle with partial data adoption and inconsistency.
- Unstructured Clinical Text - More than 70% of clinical information is buried in free-text notes, scanned PDFs, radiology narratives, and discharge summaries. Without strong NLP pipelines, most ML models are starved of context. Converting unorganized text into structured, usable inputs becomes a major barrier.
- Data Quality is Still Highly Variable - Incomplete histories, duplicated records, inconsistent timestamps, missing vitals, and unreliable device readings create considerable friction. ML models amplify these inconsistencies.
- Regulatory Needs Keep Changing - Most healthcare companies don’t yet have dedicated policy specialists, so every time there’s some change in regulations, model review results in a lengthy and repetitive cycle of iterations, paperwork, and approvals.
- Model Drift – As clinical data gets frequently updated with new medications, disease patterns, guidelines, etc., model drifts happen faster than you would expect. Healthcare teams don’t have any option but to continuously retrain ML models. This mostly happens in population health and early-warning systems.
Best Practices for Implementing AI/ML Models in Healthcare Data Workflows
Now, to address those challenges, here’s a set of practices that we now see as non-negotiable when building scalable healthcare data pipelines using AI and ML models:

- Start with a Clean, Structured Data Foundation
AI-powered data pipelines are only as reliable as the input. Establishing unified schemas, consistent identifiers, and strict data validation early should be your priority to avoid compounding quality issues downstream.
- Prioritize Privacy by Design
Build de-identification, consent tracking, PHI masking, and data access governance into the pipeline itself. Do not layer them later. Compliance has to stay automatic, not reactive.
- Use Modular Pipelines for Model Integration
The modular design approach is relevant here as well. Keep model training, inference, and monitoring as modular components. This design allows iterative updates and quick model swaps without disrupting upstream or downstream processes.
- Deploy Real-Time Quality Monitors
Set up automated drift detection, missing data alerts, lineage tracking, and outlier monitoring. Continuous feedback keeps AI predictions stable even as clinical or operational data changes.
- Design for Cross-System Compatibility
AI pipelines work best when data flows without any friction across EHRs, research systems, and analytics tools. This is the very reason teams following FHIR and HL7 standards for interoperability are ahead in realizing the benefits of AI-driven data engineering in hospitals.
- Scale Infrastructure Responsively
Since elastic scaling keeps pipelines cost-efficient without having any impact on inference speed or data throughput, it’s best to use adaptive resource allocation and containerized workloads.

The Next Phase of AI in Healthcare Data Engineering
AI’s growth curve has been exponential recently. It’s rare to see a field reinvent itself this fast, and so, the next 5-10 years will shape the long game.
As of now, the future trends in AI-based healthcare data engineering will be around self-learning systems. Our data engineering team follows the latest shifts through workshops and industry conferences led by major cloud vendors. They are already working with early prototypes of AI-optimized pipelines that are intelligent enough to adapt, heal, and optimize themselves. In other words, the infrastructure is starting to think for itself.
Generative AI is also steadily finding its place inside healthcare data ecosystems. Teams are using it for data harmonization, to summarize clinic text to feed pipelines, map codes, and fill gaps in unorganized data sets. Most of this is still in the sandbox stage, but the potential is obvious, as long as the safety constraints are followed.
What Healthcare Enterprise Leaders Should Prioritize Right Now
The most important move for healthcare organizations right now is to start modernizing quietly, but deliberately. It can be small, but it has to be strategic. Automate a few workflows, run pilots on clinical or claims data, and learn from the feedback loop. Don’t wait for the perfect architecture. The teams already experimenting are the ones who’ll be ready when AI-driven data systems become the default.If you’re planning a transition, consider working with us. Every insight in this blog comes from our own experience, and we assure you we’ll handle your project with the utmost technical discipline./u>Our AI research and engineering team is continuously upskilled on the latest breakthroughs, and we have a dedicated R&D desk for AI experimentation. If you’re not ready for a full-scale rollout, run a pilot project with us.Connect with our team, and we’ll get back to you within 48 hours with a complimentary strategy session.
FAQs
What is AI-driven data engineering in healthcare?
How is AI being used in healthcare data?
What types of AI and ML models are used in healthcare data engineering?
What are the challenges in adopting AI for healthcare data pipelines?
How does AI support real-time healthcare analytics?
Is AI replacing data engineers in healthcare?
What’s the future of AI in healthcare data pipelines?


Explore More Topics
Ready to brush up on something new? We've got more to read right this way.
Get top Insights and news from our technology experts.