


We used ECS to organize and run all application containers. It helped us with clear separation of workloads and greater control over how services were deployed and maintained.

Recognized for AI Excellence at 2026 Globee® Awards - Read More
About the Client
TopDawg is one of the largest and most popular dropshipping platforms for retailers and wholesale suppliers in the USA. It has several marketplace apps available on Shopify. The company has over 500,000 products in stock, provided by more than 3000 suppliers who dropship from warehouses.
Country
USA
Industry
Digital Commerce
Time Invested
9 Weeks
Team Size
6 Experts
Business Problem
The client’s website was facing random, unpredictable outages throughout the day. Traffic spikes and background activities were frequently triggering the system and causing sudden service interruptions. The site architecture was highly complex, and the lack of knowledge transfer from the previous development team made it difficult for the client team to diagnose the root causes of the crashes.
Project Overview
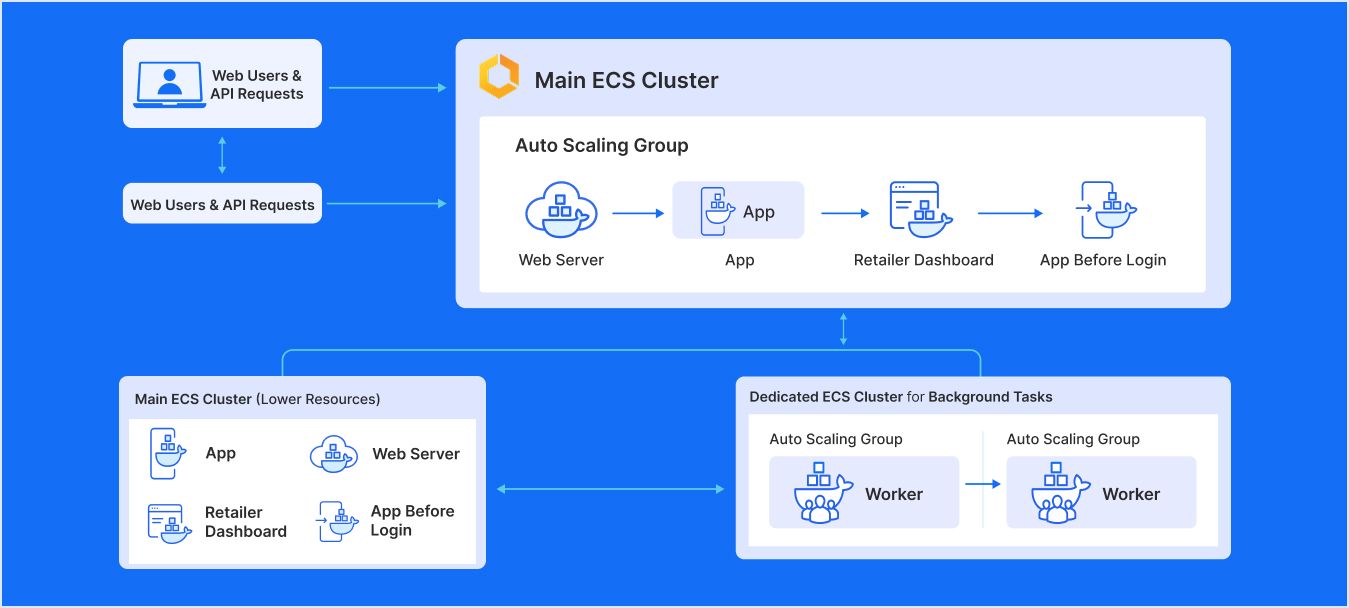
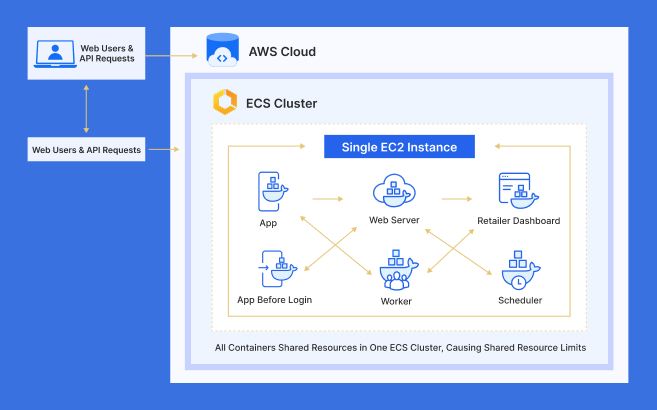
During our analysis, we found out that the website was using six Docker containers – app, web server, retailer-dashboard, app-before-login, worker, and scheduler - within the same ECS cluster on a single EC2 instance. The worker and scheduler carried the heaviest background tasks. So, when these containers were overloaded and restarted, they caused the whole website to restart with them, as every container was marked essential.
Our software architecture team realized that worker and scheduler didn’t need to be in the same cluster as the rest of the containers. We separated those two high-load services into a dedicated ECS cluster with their own EC2 resources. The other four containers were kept in the original cluster with lower resources.
This prevented heavy background tasks from affecting the web-facing containers. Since the worker and scheduler could restart without affecting the main website, the site stopped going down unexpectedly. The four regular containers did not need a high CPU or memory anymore, and the new worker/scheduler EC2 machine could be configured with a higher capacity to handle heavy loads.
Client Remarks

Our system uptime has remained above 99.9%, and platform response times have dramatically improved, providing a better overall user experience. These measurable improvements have helped us enhance retailer satisfaction, increase retention, and support consistent monthly revenue growth.
Darren DeFeo
CEO, TopDawg
With no documentation and an overloaded deployment model, we had to trace every interaction from scratch. Once we isolated the high-load services and rebuilt the deployment structure, the entire platform responded with a level of stability it had never reached before.

Mounil Shah
Project Lead at Radixweb
Key Challenges
- The architecture had multiple interconnected services with no documentation, which required extensive analysis to understand how each component behaved under load.
- The previous development team provided no knowledge transfer, so our engineers had to recreate the system’s logic and deployment decisions from direct observation.
- All containers were running within a single ECS cluster. It was difficult to isolate which workload triggered the recurring outages.
- Background processes consumed far more resources than expected, and their failure patterns were irregular. This delayed early diagnostics.
Solutions Provided

Architecture Review and Stakeholder Approval
Our architects carried out an in-depth analysis of the website to understand the source of instability and failure path. Once the issues were clear, we shared our findings with the client, explained the recommended adjustments, and finalized the project plan.

Isolating High-Load Background Services
Our architects carried out an in-depth analysis of the website using cloud computing telemetry and intelligent monitoring to understand the source of instability and failure path. Once the issues were clear, we shared our findings with the client, explained the recommended adjustments, and finalized the project plan.

Cluster Setup and Resource Allocation
A dedicated ECS cluster was built and supported by its own EC2 instance exclusively for high-load operations. This provided a controlled environment with customized CPU, memory, and scaling components. Heavy workloads no longer interfered with user-facing processes.

Migration of Background Workloads
We migrated the worker and scheduler containers to the dedicated cluster. We tested each component, checked for consistency in job execution, and monitored stability during peak activity. Running these services separately helped remove the chain reactions that previously caused system-wide restarts.

Workload Refinement and Resource Tuning
Based on how each container consumed memory during routine and peak activity, we refined container responsibilities and adjusted resource limits. The website could handle load more predictably and avoid the instability that came from competing system demands.

Staged Validation and Performance Monitoring
We introduced a staged validation cycle to observe website behavior under real-world conditions. The support team monitored restart frequencies and throughput across all services using automated performance dashboards and intelligent alerting systems to confirm that the new deployment model functioned as intended.
Get Expert Support
Share your challenge and we return with an action-ready solution outline, including scope, timelines, and delivery expectations.
How We Built on AWS
Amazon ECS
Amazon EC2
EC2 instances provided the underlying compute capacity for different workload groups. By assigning dedicated instances to high-load services, we enabled predictable performance and eliminated resource conflicts.
Amazon CloudWatch
CloudWatch helped us track container behavior, load patterns, and restart frequencies. These insights were essential for understanding root causes and monitoring platform stability.
AWS IAM
IAM allowed us to implement role-based access in the environment. Operational changes, deployments, and monitoring activities were controlled and aligned with the latest cloud security standards.
Business Benefits
Following the architectural revisions and workload adjustments, the platform delivered measurable improvements in performance and stability. These gains strengthened everyday operations and gave the business a more predictable service base.

Predictable Platform Performance
The application no longer experienced unpredictable outages. With high-load services isolated, the platform delivered 99.9%+ uptime. Daily operations now run without interruptions or service degradation.

Improved Operational Efficiency
Teams could manage orders and customer interactions without delays caused by system slowdowns. The reduced disruption improved internal workflows and resulted in a 50%+ reduction in platform support tickets.

Scalability and Growth Readiness
With workloads separated and resources right-sized, the platform could absorb traffic surges nearly 3-4x higher than before. The TopDawg team can now launch new features and expand operations without any constraints.
Lower Infrastructure Overhead
As we optimized resource allocation across clusters, our client could minimize unnecessary compute consumption. This created cost efficiencies while still ensuring that heavy background services had the capacity they needed to operate efficiently.

Bring Your Most Pressing Challenge to Us
We have the capacity to start working on your problem within 5-7 Days. You receive a fixed delivery outline and recommended next steps.