
Read More

Recognized for AI Excellence at 2026 Globee® Awards - Read More
What Generative AI is in 2026 and How It Actually Works: The Implementation Reality for Tech Leaders

Dhaval Dave
Published: Feb 12, 2026

On this page
- Why the Definition of Gen AI Needs a Reset in 2026
- What is Generative AI?
- How Does Generative AI Work? From Input to Outcome
- The Core Components of Modern Generative AI Systems
- The Real Cost of Generative AI
- 3 Types of Generative AI (And Which Your Company Needs)
- Benefits of Generative AI: What It is Actually Good At
- Challenges of Generative AI: Why Most Projects Fail
- How Enterprises Should Evaluate Generative AI Today
- Generative AI is a Mature Technology with Immature Expectations
On this page
- Why the Definition of Gen AI Needs a Reset in 2026
- What is Generative AI?
- How Does Generative AI Work? From Input to Outcome
- The Core Components of Modern Generative AI Systems
- The Real Cost of Generative AI
- 3 Types of Generative AI (And Which Your Company Needs)
- Benefits of Generative AI: What It is Actually Good At
- Challenges of Generative AI: Why Most Projects Fail
- How Enterprises Should Evaluate Generative AI Today
- Generative AI is a Mature Technology with Immature Expectations
What This Article Covers: This article explains Generative AI from an enterprise perspective, focusing on how it delivers practical business value beyond experimentation. It clarifies what Gen AI systems are, how they function in real operations, where they fit within existing technology stacks, and what leaders should realistically expect in terms of use cases and outcomes.
Editor's Note: If you are looking for a beginner’s overview, this article will feel redundant. It is written for readers who already know the term and want to understand how Generative AI works within a product or organization.
Generative AI is a subset of Machine Learning that creates original content (texts, code, visuals, audio, and interactive elements) from patterns learned from massive datasets using transformer neural networks.
While it’s used as a standalone model responding to prompts in isolation, Gen AI now functions as a system where multiple layers work together around the model. Production Gen AI delivers business value through orchestrated LLMs, enterprise data retrieval, and validation systems, not single models.

Why the Definition of Gen AI Needs a Reset in 2026
Generative AI is a familiar territory now. Most leaders reading this already know how it works at a conceptual level or have explored it in some form. The literacy gap closed in 2024. The open question for many organizations is how it works once it is placed inside production software and exposed to real constraints.
In practice, Gen AI is operated by everything around the model. How context is assembled, what information the system is allowed to reference, how outputs are constrained, and how failures are handled all matter as much as the model itself. Most fail because executives don’t understand the full system complexity.
Our article approaches explaining Generative AI from that operational perspective. Instead of reintroducing the concept, we explain what modern Gen AI systems mean, how they function end to end, where they tend to fail, and why many implementations stall after early success.
What is Generative AI?
Gen AI operates as a 12-18 component system in production environments. It includes GPU clusters for inference and fine-tuning, agent orchestrators for multi-step reasoning, RAG pipelines to ground outputs in enterprise data, and observability stacks that track latency, cost, drift, and response quality.
For business leaders, Generative AI delivers value not because a model can generate text, code, or images, but because the surrounding system makes those outputs accurate, auditable, secure, and operational at scale. The real differentiation comes from how well you design, integrate, and run the system over time.
The Mistake of Understanding GenAI as an API Call
Direct model invocation works well in controlled environments. where inputs are simple, stakes are low, and no one tracks latency, cost, misuse, or data lineage. This is why many pilots are impressive in demos but collapse in production. The surface area is small, and the system has very little to account for beyond producing a response.
At production scale, you must handle noisy, ambiguous inputs, secure data, enforce policies, and keep responses consistent across thousands of users and Generative AI use cases. Without those controls, systems become fragile, expensive, and untrustworthy for enterprise workloads. Toy-to-production gaps persist as the #1 reason 95% of Gen AI pilots fail.
How GenAI Should be Understood Instead
GenAI should be understood as a coordinated system where the model is responsible for content generation, but it is supported by layers that shape what the model sees, how it responds, and how its output is handled afterward. The foundation model itself, in most deployments, accounts for roughly 8% of the overall cost and complexity.
Context comes from retrieval layers and data pipelines. Uncertainty is handled through guardrails, validation, and human-in-the-loop reviews. And accountability depends on observability, audit logs, access control, and governance. Together, these components manage uncertainty and enforce accountability.
When Generative AI is understood with system-level thinking, it becomes less mysterious and more manageable. This fundamental shift from consumer curiosity to enterprise infrastructure makes Gen AI just not a model choice but like ERP or any other critical enterprise system implementations.
Consumer Gen AI vs. Production Gen AI
| Factor | Consumer Gen AI (2023) | Production Gen AI (2026) |
|---|---|---|
| Cost | ~$500/month | ~$3M/year |
| Team | 1 prompt engineer | 3-5 MLOps engineers |
| Timeline | 2 weeks | 6-18 months |
| Output | Blog posts | Revenue systems |
| Risk | None | Career defining |
How Does Generative AI Work? From Input to Outcome
Generative AI processes user requests through a 5-step pipeline that includes problem framing, contextual grounding, controlled generation, post-generation control, and feedback logging. This system orchestration (not model choice) delivers reliable enterprise outcomes and manages cost, risk, and compliance.
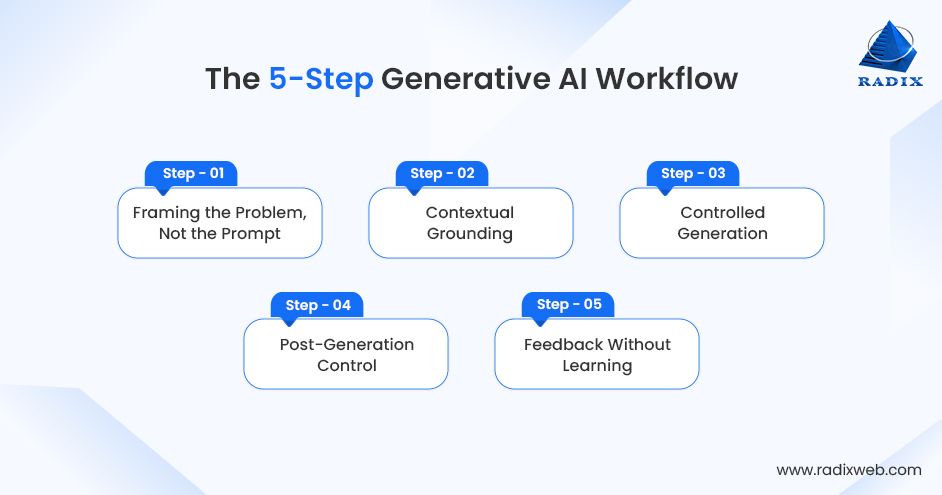
Step 1: Framing the Problem, not the Prompt
Prompts are more popular because they are visible. But what they are in reality is a downstream artifact of earlier decisions. Before any prompt is constructed, generative AI platforms have already made choices about intent, scope, and acceptable outcomes. Framing replaces prompt engineering with intent classification running at near 100% accuracy in mature systems.
What happens is:
"Write Q4 summary" > Intent classifier > "Summarize pipeline data from CRM for executive presentation, 300 words maximum, exclude confidential pricing"
System adds user role, department policies, and recent conversation history automatically.
Step 2: Contextual Grounding
Contextual grounding means allowing Gen AI systems to use/avoid specific information when generating answers. Production Gen AI systems diverge sharply from generic chat models here.
Contextual grounding typically involves:
- Selecting approved sources of information
- Excluding outdated, sensitive, or irrelevant data
- Structuring context so the model understands priority and scope
This step exists to reduce hallucination, but it cannot eliminate it entirely. With a controlling context, Generative AI systems generate plausible outputs that are most likely to align with enterprise demands.
Step 3: Controlled Generation
Gen AI models create content within strict constraints. Production systems override "be creative" defaults with enterprise parameters, which are set to limit variability, response length, and speculative reasoning. These constraints are intentional.
Here are some examples of key controls:
- Temperature: 0.1-0.3 (predictable vs. random)
- Max tokens: 2048 input, 1024 output (cost/latency cap)
- Stop sequences: "Never include," "Confidential," pricing clauses
Note that the "magic creativity" executives saw in demos becomes deliberately constrained behavior as production Gen AI systems prioritize reliability over novelty.
Step 4: Post-Generation Control
Raw model output never reaches users. Response passes validation to ensure format, accuracy, policy compliance, and quality before delivery. If an output fails validation, Gen AI tools may retry with adjusted constraints or escalate it for review. This layer is where enterprise accountability is enforced.
Four validation gates are:
- Format check - JSON structure, bullet lists, email signatures intact
- Fact verification - Cross-check key claims against retrieved grounding data
- Policy scan - Regex + classifiers block PII, confidential terms, violations
- Quality scoring - Secondary model rates confidence and relevance
Step 5: Feedback Without Learning
Production Gen AI does not "learn" from user feedback in real time. This is because if you allow live learning from user input, there will be significant risks around data leakage, bias reinforcement, and even compliance. Instead, feedback is typically used to:
- Identify failure patterns
- Adjust prompts, context rules, or constraints
- Improve retrieval and validation logic
- Inform future model updates through controlled processes
Systems powered by Generative AI for business improve through engineering (routing, retrieval tuning), not self-improvement.
Core Components of Modern Generative AI Systems
Modern Gen AI systems work with the following pattern - analyzing intent, assembling context, invoking the model within constraints, and validating the result before it reaches a user or downstream system. The system around the model has been designed to control what the model reads, how it responds, and what happens to its output afterward.
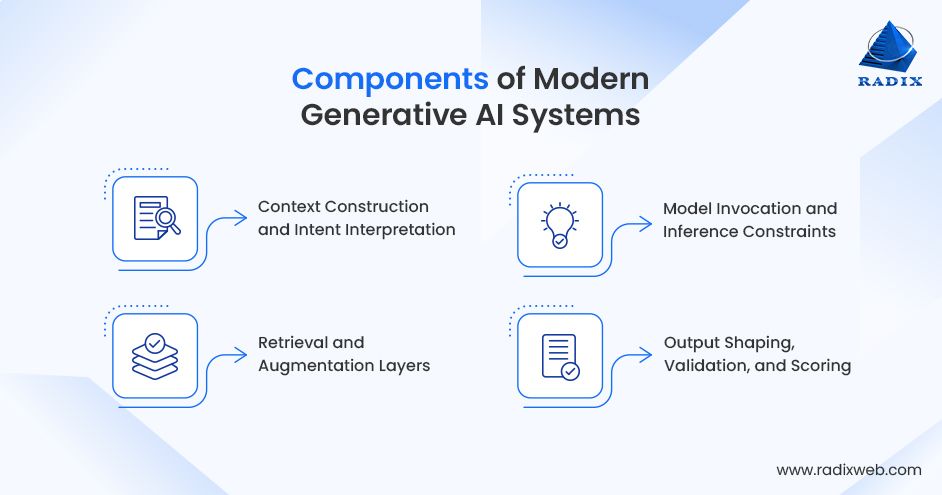
1. Context Construction and Intent Interpretation
Before a model is invoked, a GenAI system interprets user intent and constructs a controlled context that determines what information the model can use and how it should respond.
- Intent detection: Classify what the user is trying to do (e.g., summarize, compare, generate code, draft an email).
- Role and permissions check: Map the user’s identity, department, and access level to what data and actions are allowed.
- Context expansion: Attach recent conversation, relevant records (account, deal, ticket), and business rules to the request so the model sees the full picture.
- Constraint injection: Add instructions about tone, length, compliance, and do‑not‑touch areas (e.g., “never change legal clauses,” “do not show internal IDs”).
2. Retrieval and Augmentation Layers
In production, GenAI pulls fresh, domain‑specific knowledge from enterprise systems in addition to pretraining information. This is why retrieval‑augmented generation (RAG‑style patterns) dominate real deployments.
- Document selection: The system searches internal sources (docs, tickets, CRM notes, policies) for passages related to the interpreted intent.
- Chunking and filtering: Long documents are broken into smaller pieces and filtered for relevance, recency, and access level.
- Context packaging: The most relevant snippets are bundled with the user’s refined request as “grounding context.”
3. Model Invocation and Inference Constraints
Only after intent and context are prepared does the system call one or more models, under strict constraints like temperature limits, output length controls, and policy guardrail.
- Temperature and randomness: Lower values produce stable, predictable answers, while higher values increase creativity but also hallucination risk. In most enterprise flows, temperature is kept low to prioritize reliability over novelty.
- Maximum length: Hard caps on input and output size prevent runaway cost and keep latency acceptable.
- Routing policies: Simple requests go to smaller, cheaper models; complex or sensitive ones go to larger or more specialized models.
- Safety and compliance prompts: System instructions explicitly forbid leaking sensitive data.
4. Output Shaping, Validation, and Scoring
The first model response is not usually what the user sees. Modern Gen AI applications run responses through additional layers to shape and validate them before delivery.
- Format enforcement: Ensuring the answer matches the expected structure (JSON, bullet list, step‑by‑step plan, email draft).
- Factual and policy checks: Optional secondary passes compare claims against authoritative data or rules to flag or correct likely hallucinations or policy violations.
- Risk and quality scoring: Heuristics or secondary models score each answer for confidence, sensitivity, bias, or toxicity. Low‑scoring responses can be revised or escalated for human review.
- Logging and attribution: The system creates an audit trail for compliance and post‑incident analysis that includes which model responded, and which validations were applied.

The Real Cost of Generative AI
The LLM model license or API call costs $0.03-$15 per million tokens, which is less than 8-15% of total spend. Production Gen AI systems need considerable investment because 85-92% goes to infrastructure, data pipelines, and specialized engineering. Generative AI costs are driven more by orchestration, retrieval, validation, and monitoring than by model inference itself.
The Actual Cost Breakdown
| Category | What You Pay For | % of Total |
|---|---|---|
| GPU Infrastructure | H100 cluster (16 GPUs), inference serving | 65%+ |
| Data Systems | Vector databases, RAG pipelines, enterprise connectors | 15-20% |
| Engineering | MLOps engineers (fine-tuning, deployment) | ~15% |
| Model/API | GPT, Claude Sonnet, Gemini, Dall-E | <10% |
Why Models are the Cheap Part
- API Economics: Model providers compete aggressively on price, for which costs continue dropping.
- Open Source: DeepSeek-R1, Mistral Devstral 2, and LLaMA family eliminate licensing entirely.
- Commodity: Model selection becomes a 2% decision as infrastructure dominates.
Infrastructure Dominates Everything
GPU clusters of Gen AI platforms scale linearly with concurrent users, not model parameters. A single H100 supports 100-200 simultaneous enterprise queries. 10,000 executives, for example, need 50+ GPUs running 24/7. Inference serving layers add redundancy, load balancing, and caching that multiply base compute costs.
Data Systems are Expensive
Your Salesforce, Workday, and internal documents don't become AI-accessible by default. Enterprise-scale retrieval infrastructure costs multiples of consumer APIs because:
- Every document requires indexing and metadata
- Access controls must filter by user, department, compliance status
- Real-time sync with source systems
- Query optimization across millions of enterprise records
The Engineering Multiplier
Production Gen AI technology demands specialized MLOps teams that traditional IT cannot provide. Enterprises need 6-10 engineers with distinct expertise like Generative AI developers, platform engineers, data engineers, ML engineers, and security engineers. These aren't generalist IT roles, so each demands specialized skills absent from most corporate IT departments, which in turn requires hefty investment.
It's safe to say that CTOs debating "Llama vs GPT-4" miss the point entirely. Infrastructure capacity, data connectivity, and MLOps maturity determine ROI 10 times more than model selection. Hence, the smartest C-suites invest in systems engineering expertise, not model shopping.
3 Types of Generative AI (And Which Your Company Needs)
Production Generative AI falls into 3 categories - Conversational Agents, Content Generators, and Agentic Systems. Most companies start with Gen AI agents for immediate ROI, add content generators for scale, and build agentic solutions only after controlling orchestration.
Type 1 - Conversational Agents
Conversational agents answer questions and handle knowledge work using your company's live data. for example, "Ask HR about benefits," "Sales team queries CRM pipeline," or "Finance pulls Q4 forecast insights." These systems connect Gen AI to your internal systems through RAG pipelines without complex multi-model orchestration.
Primary Use Cases
- Executive Q&A over dashboards, reports, Slack threads
- Employee support replacing ticket systems
- Sales/customer success researching accounts
- Compliance/policy lookups with citation trails
Type 2 - Content Generators
Content Generators create documents, code, and assets at scale. These systems produce customer emails, generate test cases from requirements, create wireframes from specs, or draft technical documentation from codebases. Multiple model types often collaborate (LLM for text, diffusion models for visuals).
Primary Use Cases
- Marketing - Personalized campaigns, A/B test copy
- Engineering - Test cases, documentation, boilerplate code
- Product - Wireframes, user flows from requirements
- Customer Success - 1:1 email drafts, renewal summaries
Type 3 - Agentic Systems
AI agents are autonomous digital workers that complete multi-step business processes end-to-end. Multiple specialized agents collaborate under central orchestration to replace entire workflows. Agentic Gen AI systems work best when they assist human operators or automate internal processes with strong constraints, rather than acting independently.
Primary Use Cases
- Sales: Lead qualification, demo scheduling, follow-up
- Customer Success: Churn risk, retention playbook, executive escalation
- Operations: Vendor research, contract drafting, compliance review
- Product: Bug triage, dev assignment, status updates
Benefits of Generative AI: What It is Actually Good At
Generative AI excels at pattern transformation (emails, summaries, code completion), data summarization, classification, and assisted reasoning. Production Gen AI platforms work best for repetitive, well-defined tasks with clear success metrics.
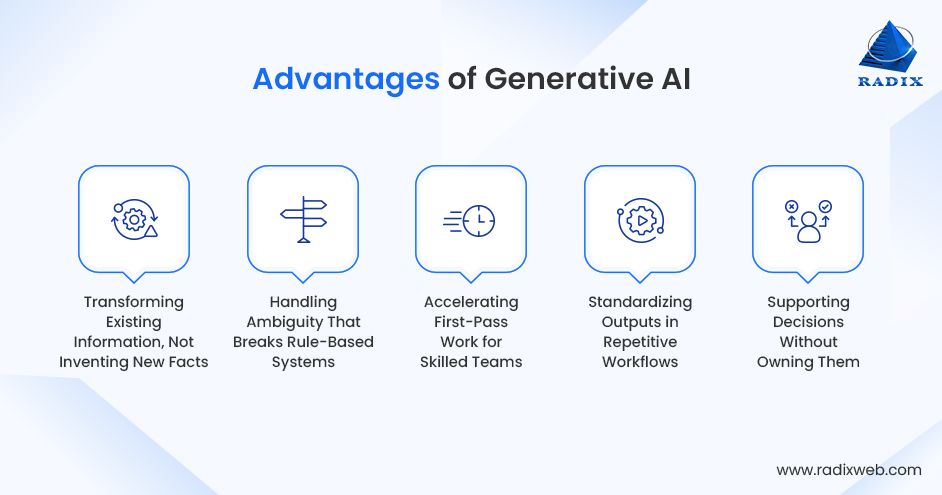
Transforming Existing Information, Not Inventing New Facts
Gen AI is strongest at transforming, summarizing, and restructuring existing information rather than creating net-new facts. Summaries, rewrites, classifications, comparisons, and extractions all benefit from probabilistic reasoning without requiring factual originality.
Handling Ambiguity That Breaks Rule-Based Systems
When inputs are incomplete or ambiguous, but the outcome still needs to be directionally correct, Generative AI performs well. Traditional systems struggle when inputs do not match predefined patterns. Gen AI can interpret intent, infer relationships, and produce usable outputs even when the request is loosely framed.
Accelerating First-Pass Work for Skilled Teams
Generative AI is effective at producing first drafts, initial analyses, and preliminary outputs that humans can refine. As Gen AI automates the time-consuming early steps, systems that treat it as an accelerator rather than an authority tend to scale more successfully.
Standardizing Outputs in Repetitive Workflows
When constrained correctly, Gen AI produces uniform structure, tone, and formatting at scale. This is particularly valuable in enterprise environments where variability comes from human execution instead of business logic.
Supporting Decisions Without Owning Them
Generative AI works best as a decision support layer. What it should not do is make final calls in high-stakes contexts. Enterprises must maintain this boundary to benefit from GenAI’s reasoning ability. This distinction is one of the clearest indicators of mature deployment.
Gen AI Failure Areas: What It Is Not Good At
Production GenAI fails on high-stakes judgment tasks that need causal reasoning, regulatory nuance, competitive context, or liability (strategy, legal review, security analysis, pricing). These domains demand human synthesis beyond pattern matching.
Tier 1 - Strategic Judgment
- Market entry strategy (ignores local dynamics)
- Pricing optimization (misses competitor reactions)
- M&A due diligence (overlooks subtle risks)
- Executive messaging (wrong tone destroys trust)
Tier 2 - Regulatory/Compliance
- Legal contract review (misses ambiguous clauses)
- Compliance gap analysis (invents regulations)
- Audit preparation (confabulates evidence)
- HR policy interpretation (creates liability)
Tier 3 - Security/Technical Risk
- Vulnerability detection (mostly false positives)
- Architecture recommendations (ignores constraints)
- Production deployment automation (breaks systems)
- Incident response planning (shallow analysis)
Challenges of Generative AI: Why Most Projects Fail
70% of enterprise Gen AI projects fail to reach production because executives underestimate data complexity and infrastructure requirements. Hallucinations represent a fundamental limitation, while infrastructure consumes 80%+ of budgets despite 2% model costs.
Hallucinations are Fundamental
In 2023, New York lawyers in Mata v. Avianca were sanctioned for submitting a court brief citing six fake cases invented by ChatGPT. The Gen AI model confidently fabricated non-existent legal precedents.
Hallucination is a core model behavior. Large Language Models predict "statistically likely" text sequences, not verified facts. When training data lacks complete information or contains gaps, models confidently fill blanks with plausible fabrications.
C-suite implication: Every hallucination-protected answer requires 3-5x more infrastructure than raw model inference. Hence, leaders need to budget accordingly.
The 80/20 Infrastructure Trap
It is relatively easy to reach the first 80 percent. A capable model, a working prompt engineered over a weekend, and visible output impress stakeholders immediately. That early demo success creates the dangerous illusion that the hardest work is done.
The remaining 20 percent destroys most systems. This invisible layer contains:
- Orchestration: Multi-agent coordination across specialized models
- Retrieval: Indexing enterprise documents with access controls
- Monitoring: Causal tracing linking "model decision → business outcome"
- Cost controls: Dynamic model routing saving millions annually
- Governance: Immutable logs proving regulatory compliance
C-suite reality: The flashy 80% demo gets funding approval. The 20% of engineering behind the scenes determines ROI. 70% of projects die here because executives celebrate early wins without budgeting for production work.
How Enterprises Should Evaluate Generative AI Today
C-suite leaders should evaluate Gen AI by system maturity, ROI potential, infrastructure readiness, and team capability. Production success requires evaluating orchestration, retrieval accuracy, cost controls, and governance over raw model intelligence.
The questions below reflect how GenAI actually behaves once it is embedded in system workflows.
1. Start with the job-to-be-done, not the model
Leaders should evaluate Generative AI by the specific job it must perform and the acceptable range of outcomes, not by model capability or popularity.
Before discussing models, clarify:
- What decision or workflow this system supports
- How often it will be used
- What happens when it is wrong
If the job cannot be clearly bounded, GenAI will struggle in production. Precision here reduces risk everywhere else.
2. Evaluate the system, not the demo
A Gen AI demo shows generation quality, not production readiness.
Ask to see how the system handles:
- Ambiguous or low-quality inputs
- Conflicting information
- Policy violations
- Retries, fallbacks, and rejection paths
Demos that only show best-case prompts are incomplete. Production systems are defined by how they behave when inputs are messy and expectations are unclear.
3. Demand clarity on context and data boundaries
Reliable Gen AI applications depend on strict control over what information the system can access and use.
Leaders should require clear answers to:
- What data sources are allowed to influence outputs
- How freshness and relevance are enforced
- Whether sensitive or regulated data is excluded
- How data access is audited
Weak data boundaries are a leading cause of hallucinations and compliance issues.
4. Insist on observability and ownership
If a GenAI system cannot explain why it produced an output, it cannot be trusted at scale.
Production-grade systems provide:
- Visibility into inputs, context, and outputs
- Monitoring for drift, failure rates, and latency
- Clear ownership for quality, cost, and risk
Without observability, teams are forced to guess. Without ownership, issues linger unresolved.
5. Evaluate cost predictability, not just price
The true cost of Generative AI is determined by system behavior, not model pricing.
Leaders should look for:
- Cost breakdown across orchestration, retrieval, validation, and monitoring
- Usage limits and escalation controls
- Scenarios where costs spike unexpectedly
Predictability matters more than low initial cost. Unbounded systems rarely stay cheap.
6. Separate assistance from authority
Mature GenAI systems assist decisions; they do not own them.
Ask explicitly:
- Where does human approval remain mandatory?
- Which outputs are advisory versus actionable?
- What happens when the system is uncertain?
Systems that blur this boundary tend to lose trust quickly.

Generative AI is a Mature Technology with Immature Expectations
The core Gen AI models are remarkably capable and increasingly commoditized. Despite that, many enterprise initiatives still treat them as magic fixes that will improve strategy, culture, data, and process all at once. The result is a widening gap where PoCs impress in demos, but production systems die in pilot or overrun budgets.
For C‑suite leaders, the shift is simple but uncomfortable - stop asking, “How smart is the model?”. Their question should be “How strong is the system around it?”. Mature use of Gen AI means respecting its strengths (pattern-heavy, repeatable work with clear success criteria) and its limits (high‑judgment, high‑liability decisions that still demand human ownership). It means funding the infrastructure with the same seriousness as the model itself.
As a Generative AI development partner, this is exactly where our work starts. Instead of selling you “a model,” we help C‑suite teams:
- Identify a narrow set of high‑ROI, low‑risk use cases aligned with your P&L and data reality.
- Design and build the surrounding system that makes Gen AI safe, reliable, and cost‑controlled in production.
- Stand up cross‑functional teams (your SMEs + our engineers) so that what we deploy is both technically sound and operationally adoptable.
Schedule a discovery session with our Technical Lead to get executive‑ready Gen AI capabilities. Let us help you avoid the traps that have already sunk so many “AI transformation” programs.
Frequently Asked Questions
What is Generative AI in simple terms?
Is Generative AI just large language models (LLMs)?
What makes Generative AI different from traditional AI systems?
What are the most popular Generative AI use cases for enterprises?
How long does enterprise GenAI deployment actually take?


Explore More Topics
Ready to brush up on something new? We've got more to read right this way.
Get top Insights and news from our technology experts.